
At forstå sprogmodeller
Dette indlæg udforsker ChatGPT’s fundament baseret på kunstige neurale netværk, dets træningsproces med enorme datamængder, og hvordan menneskelig feedback finjusterer evnen til at forstå og generere sprog. Lær om, hvordan ChatGPT efterligner menneskelig intelligens for at revolutionere kommunikation, kreativitet, og interaktion med teknologi.

Moderne sprogmodeller er baseret på kunstige neurale netværk. Forestil dig menneskets hjerne, en utrolig kompleks struktur bestående af milliarder af neuroner. Disse neuroner kommunikerer med hinanden via synapser for at danne et omfattende netværk, der gør det muligt for os at tænke, lære og opleve verden omkring os. Neurale netværk i AI-verdenen er inspireret af denne biologiske struktur.
Et kunstigt neuralt netværk er en serie af algoritmer, der søger at genkende underliggende mønstre i en samling data gennem en proces, der minder om den måde, den menneskelige hjerne fungerer på. Dette netværk består af lag af kunstige neuroner, der er forbundet på en måde, der ligner hjernens neurale netværk.
Forestil dig en kok i et enormt, veludstyret køkken. I dette køkken er der skuffer og hylder fyldt med en utrolig mængde af ingredienser – alt fra almindelige krydderier til eksotiske frugter. Kokkens opgave er at lave et lækkert måltid ud fra de ingredienser, der er til rådighed.
Køkkenet og kokken er en analogi for et kunstigt neuralt netværk. Hver ingrediens repræsenterer en lille bid af information eller data. Når det får en anmodning om at lave en ret (svare på et spørgsmål), dykker den ned i den enorme samling af ingredienser (data) og bruger sin viden om smagskombinationer og opskrifter (læringsalgoritmer) til at lave det perfekte måltid (et præcist og informativt svar).
Ligesom du kombinerer forskellige ingredienser for at skabe nye smage, arbejder et neuralt netværk med at kombinere forskellige stykker information for at forstå og reagere på forespørgsler. Og ligesom en dygtig kok hele tiden lærer og tilpasser sig, lærer det neurale netværk fra nye data for at blive bedre til at besvare spørgsmål eller løse problemer.
Et neuralt netværk består af basalt set af kunstige neuroner, kaldet ‘units’. Der kan være op til flere millioner units i et netværk, og de er arrangeret i en række lag, som hver især er forbundne.
Nogle af dem, kendt som input-units, er designet til at modtage forskellige former for information fra omverdenen, som netværket vil forsøge at lære om, genkende eller på anden måde behandle.
Andre enheder sidder på den modsatte side af netværket og signalerer, hvordan det reagerer på den information, det har lært; de kaldes output-units.
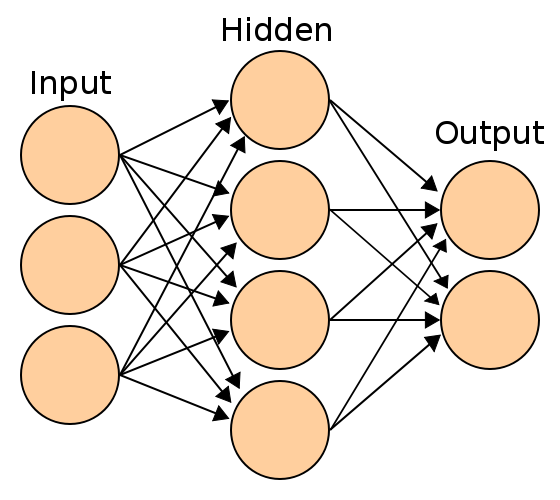
Mellem input-units og output-units er der et eller flere lag af skjulte units, som tilsammen udgør størstedelen af netværket.
Dette skjulte lag er bl.a. udtryk for træning, som modellens skabere har brugt til at skrue på vægtene i modellen, så modellen ved hjælp af maskinlæring selv kan finde ud af og lære relationen mellem forskellige variabler.
Konkret bryder en statistisk model dens data til mindre dele (variabler). For eksempel nedbrydes en tekst til enkelte ord eller orddele (kaldet “tokens”), og ved hjælp af maskinlæring lærer modellen relationen mellem de forskellige ord.
Ved at analysere meget data, f.eks. tekst, så kan modellen genkende mønstre og sammenhænge i datasættet, så som hvilke ord som typisk optræder med bestemte andre ord, og i hvilken sammenhæng ord bruges med andre ord.
Træningsprocessen for store sprogmodeller, som ChatGPT, er en kompleks og krævende opgave. Den involverer først indsamling af store mængder tekstdata, som regel fra internettet. Dette kan typisk være op til 10 terabyte tekst, der samles fra forskellige kilder, såsom hjemmesider.
Når denne tekst er indsamlet, kræves der enorm computerkraft for at bearbejde den indsamlede data. Denne proces, kendt som modeltræning, kan ses som en form for komprimering af internetdata.
Modellen lærer at forstå og forudsige sprog ved at analysere den indsamlede tekst. Hver parameter i modellen lagrer en del af den viden, som den har lært fra sin træningsdata.
Denne læringsproces kan sammenlignes med en form for komprimering, hvor modellen udvikler en generel forståelse af teksten, den er trænet på, snarere end at gemme en eksakt kopi.
Derudover er der i de moderne sprogmodeller et Reinforcement Learning from Human Feedback (RLHF) aspekt af træningen. Det er en tilgang inden for maskinlæring, hvor en model trænes til at forbedre sit output baseret på feedback fra mennesker.
I denne proces anvendes menneskelig vurdering til at guide og forfine modellens adfærd, hvilket gør det muligt at justere modellens respons baseret på menneskelig præference og vurdering. Denne menneskelige feedback kan f.eks. bestå af menneskelig vurdering af svar, f.eks. ved at rangere forskellige svar eller angive deres præferencer.
Resultatet af denne træningsproces er en sprogmodel, der kan generere og forstå sprog baseret på mønstre og viden, den har erhvervet fra træningsteksten.
Præcis hvordan denne proces fungerer, det kan ledende AI-forskere ikke engang præcist forklare.
AI-forsker Sam Bowman fortalte f.eks. i juli 2023 til internetmediet Vox, i en artikel med titlen: ‘Even the scientists who build AI can’t tell you how it works’:
“If we open up ChatGPT or a system like it and look inside, you just see millions of numbers flipping around a few hundred times a second. And we just have no idea what any of it means”
Men meget forenklet er mange moderne generative AI-systemer grundlæggende statistiske modeller, som forudsiger næste ord ved hjælp af maskinlæring, hvorved de kan genkende mønstre og sammenhænge i sit datasæt.

Dette indlæg fremhæver udviklingen af moderne sprogmodeller med et særligt fokus på ChatGPT’s innovative funktionalitet. ChatGPT skiller sig ud ved at tilbyde realistisk, menneskelignende interaktion og har sat nye standarder for brugervenlighed og tilgængelighed i AI-teknologi.