
Hvilke regler er på vej fra EU?
I dette indlæg bliver du guidet gennem EU’s regler for kunstig intelligens. Her udforskes den risikobaserede tilgang, som klassificerer AI-systemer efter deres potentielle risiko, en strategi der balancerer innovation med beskyttelse af individuelle rettigheder. Du vil lære om forordningens direkte anvendelse i medlemsstater, dens fokus på autonomi og de undtagelser, der gælder for visse AI-applikationer. Kapitlet afslører også, hvordan EU ønsker at påvirke global AI-regulering og understreger vigtigheden af gennemsigtighed og ansvarlighed i brugen af AI.

AI genereret læsemusik
Titel: Bløde Synthpad Bølger
En forordning betyder en lovgivningstekst fra EU, der gælder umiddelbart i alle medlemsstater uden behov for national implementering. Dette står i modsætning til direktiver, som skal implementeres i medlemsstaterne via national lovgivning.
Det overordnede formål med forordningen er at sikre, at AI bliver et redskab, der tjener mennesker og udgør en positiv kraft i samfundet med det endelige mål at øge menneskers velfærd.
EU’s ambitiøse mål med lovgivningen er at skabe en balance mellem at fremme innovation og teknologisk udvikling, samtidig med at man beskytter borgernes rettigheder og friheder.
Med denne forordning håber EU at sætte en global standard for AI-regulering, som kan tjene som model for andre lande og regioner.
Anvendelsesområde
Når man taler om regulering af kunstig intelligens, er den første udfordring at definere, hvad man faktisk mener med “kunstig intelligens”. Dette er vigtigt, fordi forordningens rækkevidde – altså hvilke teknologier der vil blive reguleret, og i hvilken grad – er direkte afhængig af, hvordan et AI-system defineres.
Krav om autonomi
Centralt i forordningens definition er kravet om autonomi. Med dette menes, at systemet skal have evnen til at træffe beslutninger eller udføre opgaver uden menneskelig indgriben.
Når der tales om autonomi, er det ikke nødvendigvis fuld autonomi i en science fiction-forstand – som f.eks. en robot, der kan udføre alle menneskelige funktioner. I stedet refererer det til systemers evne til at træffe beslutninger eller udføre handlinger i en afgrænset kontekst, men på en måde, der ikke kræver menneskelig godkendelse i hvert enkelt tilfælde.
Dette har vigtige implikationer for, hvordan vi tænker på ansvar og overvågning. Hvis et system er i stand til at træffe beslutninger autonomt, rejser det spørgsmål om, hvem der er ansvarlig, hvis noget går galt eller ikke virker efter hensigten.
Det rejser også spørgsmål om, hvilke kontrolmekanismer der bør være på plads for at sikre, at systemets autonome beslutninger er etiske, retfærdige og i overensstemmelse med de værdier og regler, vi har i samfundet.
AI-systemer som ikke omfattes
EU har besluttet, at brug af AI-systemer til bestemte formål slet ikke skal være omfattet af forordningen, og derfor ikke begrænses af lovgivningen.
Et område, som er undtaget, er AI-systemer der udelukkende bruges til militære eller forsvarsmæssige formål. Et eksempel kunne være AI-systemer, som er designet til at beskytte kritisk infrastruktur mod hackerangreb.
Tilsvarende gælder forordningen ikke for brug af AI-systemer, der udelukkende bruges til forskning og innovation, eller for personer, der udvikler eller bruger AI-systemer til ikke-professionelle formål.
En risikobaseret tilgang
Med AI-forordningen tages der en risikobaseret tilgang til reguleringen af AI-systemer. Denne risikobaserede tilgang er designet til at differentiere mellem forskellige typer af AI-systemer baseret på det potentielle niveau af trussel, de kan udgøre over for samfundet og enkeltpersoner.
Kategoriseringen sigter mod at sikre, at de strengeste reguleringer anvendes på de mest risikofyldte AI-systemer, mens mindre restriktive foranstaltninger anvendes på lavere risiko AI-applikationer, hvilket understøtter innovation og teknologisk fremgang uden unødvendig byrde.
Det er væsentligt at fremhæve, at EU ikke ønsker at regulere selve AI-teknologien, men i stedet ønsker at regulere anvendelsen af teknologien. EU vil med andre ord fokusere på, hvad man bruger AI-teknologi til.
Ideen er, at teknologien er i hastig udvikling, og at reguleringen lynhurtigt vil blive forældet, hvis man regulerer selve teknologien. Når EU i stedet regulerer AI-systemer efter deres anvendelse, så har reguleringen i langt højere grad en mulighed for at følge med udviklingen.
I de forskellige forordningsforslag skelnes der mellem anvendelse af kunstig intelligens, som skaber 1) en uacceptabel risiko, 2) en høj risiko eller 3) begrænset risiko.
Langt de fleste AI-systemer vil falde under kategorien minimal risiko. Systemer med begrænset risiko, såsom spamfiltre, vil ikke blive yderligere forpligtet af AI-forordningen, da disse systemer kun udgør minimal eller ingen risiko for borgernes rettigheder eller sikkerhed.
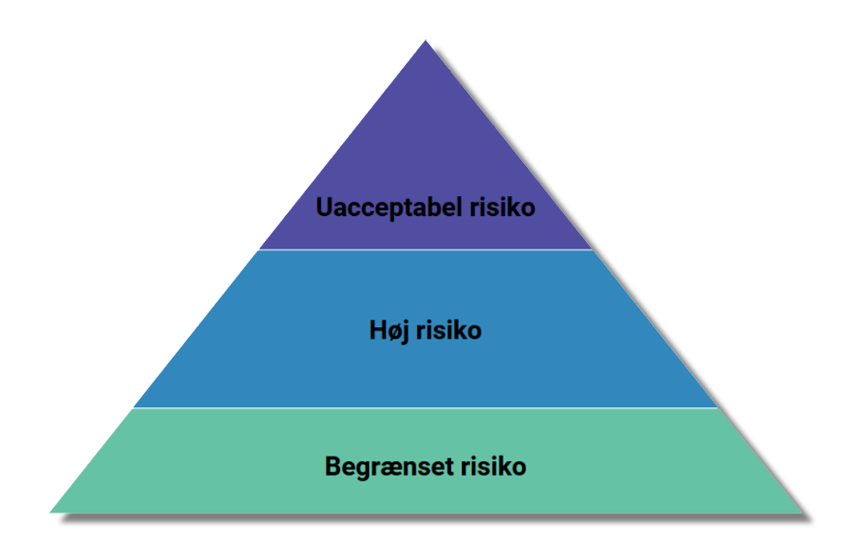
Højrisiko AI-systemer skal overholde strenge krav, herunder krav ift. kvalitetssikring af datasæt, logning af aktivitet, detaljeret dokumentation, klar brugerinformation, menneskeligt tilsyn og et højt niveau af robusthed, nøjagtighed og cybersikkerhed.
Som højrisiko-systemer betragtes f.eks. systemer som understøtter visse former for kritisk infrastruktur, f.eks. inden for vand, gas og elektricitet, men også f.eks. systemer til at bestemme adgang til uddannelsesinstitutioner eller til at rekruttere folk, eller visse systemer, der bruges inden for retshåndhævelse, grænsekontrol, retspleje og demokratiske processer.
Som uacceptabel risiko anses brug af AI-systemer, som er en klar trussel mod menneskers grundlæggende rettigheder. Disse systemer bliver forbudt. Dette omfatter AI-systemer, der manipulerer menneskelig adfærd for at omgå brugernes frie vilje, eller f.eks. systemer, der udfører “social scoring”.
Gennemsigtighedsforpligtelser
AI-systemer fungerer ofte som “sorte bokse”, hvor input behandles, og output genereres, men de præcise mekanismer for beslutningstagning forbliver skjulte for brugeren. Dette kan give anledning til bekymringer, især hvis disse systemer træffer beslutninger, der påvirker f.eks. økonomiske udfald.
Den grundlæggende tanke med gennemsigtighedsforpligtelserne er, at gennemsigtighed vil fremme tilliden til systemerne. Når folk forstår, hvordan AI-systemer træffer beslutninger, er de mere tilbøjelige til at stole på og acceptere disse systemer. Det giver også brugere, regulerende myndigheder og offentligheden mulighed for at stille spørgsmål, udfordre resultater og kræve ansvarlighed.
Forordningen indeholder krav om, at brugere af generative modeller skal informeres om, at outputtet er genereret af en AI. For eksempel, når du kommunikerer med sprogmodeller, har EU bestemt, at det skal gøres klart for brugeren, at de ved, at svarene genereres af en maskine og ikke af et menneske.
Gennemsigtighedsforpligtelserne forpligter desuden udviklerne af modeller til at afsløre, hvordan AI-systemet fungerer, i hvert fald i brede træk, så brugerne har en vis forståelse for, hvordan AI’en kommer frem til sine resultater.
Det kan også indebære forpligtelser til at forklare, hvilken type data AI-systemet er trænet på, da dette kan have stor betydning for, hvordan systemet opfører sig og hvilke bias det kan have.
For AI-systemer med begrænset risiko, såsom generative modeller, er disse forpligtelser mindre strenge end for systemer med højere risiko, såsom dem der anvendes i sundhedsvæsenet eller retshåndhævelse.
Ophavsret
Når generative AI-modeller udvikles, kræver de store mængder data for at ‘lære’ og blive i stand til at producere indhold. Disse datasæt kan indeholde tekster, billeder, musik, og andet materiale, som er ophavsretligt beskyttet. Dette rejser et væsentligt juridisk og etisk spørgsmål: I hvilken grad er det lovligt eller etisk forsvarligt at bruge disse ophavsretligt beskyttede værker til at træne et generativt AI-system?
Dette problem bliver yderligere kompliceret af, at outputtet fra en AI, der er trænet på ophavsretligt beskyttet materiale, potentielt kan efterligne eller afspejle de originale værker.
For eksempel, hvis en AI genererer et billede eller en tekst, der er markant lignende et eksisterende ophavsretligt beskyttet værk, kan dette betragtes som en overtrædelse af ophavsretten. Spørgsmålet er, hvor tæt AI-genereret indhold må ligne det originale materiale, før det betragtes som en krænkelse af ophavsretten.
Et andet aspekt af dette problem er, at det ofte er uklart, hvilken mængde og type af ophavsretligt beskyttet materiale, der anvendes til at træne disse AI-systemer. Manglen på gennemsigtighed omkring træningsdata kan føre til bekymringer omkring, hvorvidt udviklerne af AI-systemer har fået de nødvendige rettigheder til at bruge dette materiale.
Med den stadigt stigende evne og udbredelse af generative AI-systemer bliver det mere og mere presserende at udvikle juridiske rammer og retningslinjer, der både beskytter de oprindelige skaberes rettigheder og også tager højde for de etiske og moralske implikationer af AI-genererede værker og deres indvirkning på kreativitet og innovation.
Forordningen har ikke svaret på, hvordan ophavsretten overholdes i generative AI-modeller – men pålægger bare udbyderne at udarbejde en politik for, hvordan deres modeller skal overholde de gældende europæiske ophavsretsregler.

I dette indlæg udforskes, hvordan du effektivt kan implementere sprogmodeller i din organisation med et øje for ansvarlighed og sikkerhed. Indlægget opfordrer til at udforme klare interne retningslinjer, der sikrer fordelene ved AI, mens potentielle faldgruber undgås. Det fremhæver nødvendigheden af medarbejderuddannelse, regelmæssige politikrevisioner, og vigtigheden af åben kommunikation for at bygge tillid.